
Recently, we had to be creative to design a lock system in Azure Data Factory to prevent concurrent pipeline execution. There are actually two different approaches to this challenge! This blog post will describe the first approach and is co-authored by Laura de Bruin.
When and why do you want to create this ‘lock system’?
In many cases, it can lead to unwanted results if multiple pipeline runs execute in parallel. For example, when a pipeline has an hourly scheduled trigger like the screenshot below, and the previous run takes more than an hour to complete, the new instance will be triggered and nothing will prevent it from running in parallel with the already running instance!
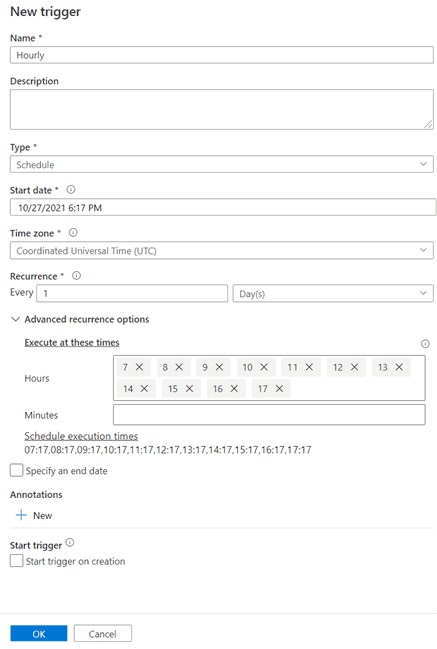
For scheduled triggers, there is nothing out-of-the-box that can help you to prevent concurrent pipeline runs. For tumbling window triggers there is a maxConcurrency property, but keep in mind that this will create a queue/backlog of pipeline runs. It will not cancel any pipeline runs. It depends on your use case if you really want that behavior. The Docs describe it like this:
The number of simultaneous trigger runs that are fired for windows that are ready. For example, to back fill hourly runs for yesterday results in 24 windows. If maxConcurrency = 10, trigger events are fired only for the first 10 windows (00:00-01:00 – 09:00-10:00). After the first 10 triggered pipeline runs are complete, trigger runs are fired for the next 10 windows (10:00-11:00 – 19:00-20:00). Continuing with this example of maxConcurrency = 10, if there are 10 windows ready, there are 10 total pipeline runs. If there’s only 1 window ready, there’s only 1 pipeline run.
Introducing two locking system approaches
We designed two different locking system approaches. The first design checks the pipeline run history to verify if any of the runs are still in progress. We will explain this design in detail in this blog post.
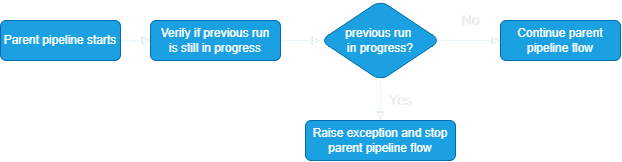
The second design works with a global parameter that holds the ‘lock’. At the start of the pipeline, we verify the value of the lock and only continue if it is not locked (false). We then change the value to locked (true) and after all activities have run successfully we change the value back to not locked (false). If meanwhile any other pipeline starts, it will find the value in locked state (true) and stop execution on the spot.
Important note: only the first design will currently work in Azure Synapse Analytics pipelines, as global parameters are not available there! Please help and vote for this existing idea to urge the development team to add global parameters in Azure Synapse Analytics.

This blog will continue now to describe the first design. An upcoming blog post will explain the second design in more detail.
Design #1: Create the ‘is_pipeline_running’ pipeline
Note: to copy the example pipeline below, we assume you have an Azure Key Vault available. If you want an alternative, you can also create variables in the ADF pipeline. But, having those values in the Key Vault makes it easier to deploy your solution to other environments.
Prerequisites:
- Make sure that the ADF (or Synapse) resource has read permissions on the secrets in the vault.
- Make sure that the ADF (or Synapse) resource has read permissions on its own resource. This might sound strange, but without explicitly granting this IAM/RBAC the pipeline will not be able to call the ADF REST API.
- If you are in Azure Data Factory: add a Global Parameter for the Key Vault URL
keyVaultUrl. - If you are in Azure Synapse Analytics pipelines: you can’t use global parametes yet, so make sure you replace those in the expressions with a variable or ‘hard-code’ the url.
Create a pipeline with the name ‘is_pipeline_running’, and add these parameters:
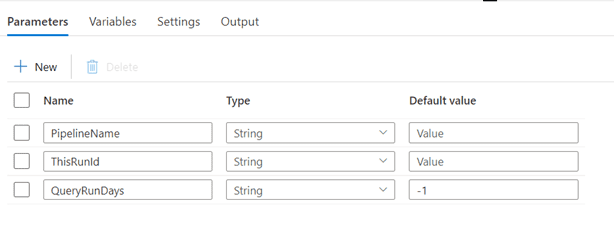
With the following activities:
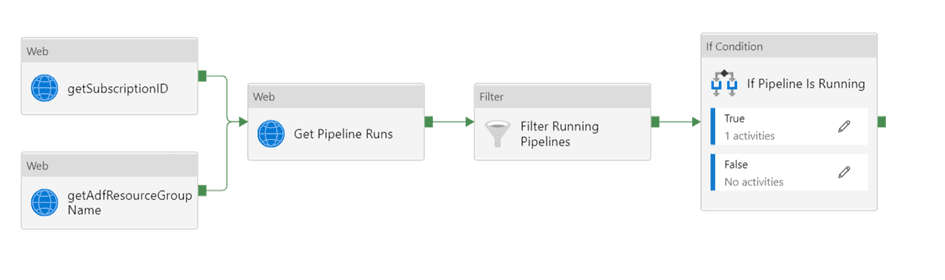
- Web activity ‘getSubcriptionID’
- Create a secret in the key vault with your subscription ID value, with name
SubscriptionID. - Get this secret value using a web activity, with this expression for the url property:
@concat(pipeline().globalParameters.keyVaultUrl,'secrets/SubscriptionID?api-version=7.0'), and this value for the resource property:https://vault.azure.net.
- Create a secret in the key vault with your subscription ID value, with name
- Web activity ‘getAdfResourceGroupName’.
- Create a secret in the key vault with the name of the resource group containing the ADF resource, with name
adfResourceGroupName.
- Get this secret value using a web activity, with this expression for the url property:
@concat(pipeline().globalParameters.keyVaultUrl,'secrets/adfResourceGroupName?api-version=7.0'), and this value for the resource property:https://vault.azure.net.
- Create a secret in the key vault with the name of the resource group containing the ADF resource, with name
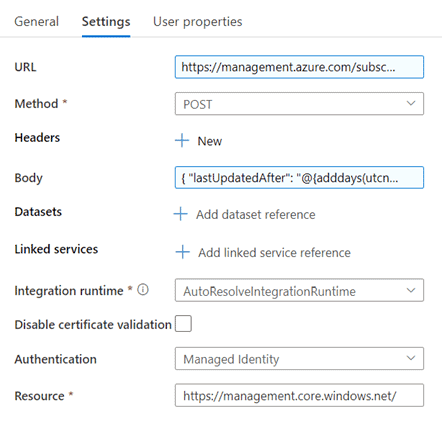
- Web activity ‘Get Pipeline Runs’
- URL: create the dynamic content to let Azure Data Factory call itself:
https://management.azure.com/subscriptions/@%7bactivity('getSubscriptionID').output.value%7d/resourceGroups/@%7bactivity('getAdfResourceGroupName').output.value%7d/providers/Microsoft.DataFactory/factories/@%7bpipeline().DataFactory%7d/queryPipelineRuns?api-version=2018-06-01. - Body: Use this code to validate if the regarding pipeline is running (status: in progress or queued) since the last QueryRunDays (default 1 day):
{ "lastUpdatedAfter": "@{adddays(utcnow(),int(pipeline().parameters.QueryRunDays))}", "lastUpdatedBefore": "@{utcnow()}", "filters": [ { "operand": "PipelineName", "operator": "Equals", "values": [ "@{pipeline().parameters.PipelineName}" ] }, { "operand": "Status", "operator": "In", "values": [ "InProgress", "Queued" ] } ] }
The settings of this activity are as follows:
- URL: create the dynamic content to let Azure Data Factory call itself:
- Filter Running pipelines
The running pipelines must meet the following conditions:- The runid is not the same as the runid of the current pipeline run.
- The pipeline contains status ‘InProgress’ or ‘Queued’:
@and(not(equals(item().runId,pipeline().parameters.ThisRunId)),or(equals(item().status,'InProgress'),equals(item().status,'Queued')))
- If condition
True: if the previous pipeline is still running, raise an error by creating a lookup activity with this query.RAISERROR('@{concat('Provided pipeline name (',pipeline().parameters.PipelineName,') still has a run in progress or queued given the query range parameters set in the properties table.')}',16,1).False: if the previous pipeline is not running there is no action and the next activity of the pipeline could start, hence we do nothing.
Design #1: How to use the ‘is_pipeline_running’ pipeline
In the pipeline that needs the ‘lock system’, add an Execute Pipeline activity that calls the is_pipeline_running pipeline. Make sure it is the first activity of the pipeline.
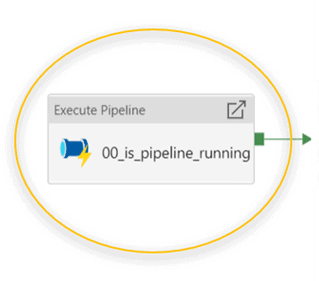
In this activity, use the following expressions for the pipeline parameters:
- PipelineName:
@pipeline().Pipeline - ThisRunID:
@pipeline().RunId - QueryRunDays: optional: this value is by default
-1to look at the pipeline runs since the past 1 day.
Design #1: Result
The new pipeline will query the pipeline run history (native ADF API call). When any previous pipeline run is still in progress it will raise an error that will surface in the parent pipeline. By default this will fail the parent pipeline as well, immediately stopping any further execution, and that is exactly the result we are aiming for! If you want, you can catch the activity failure and handle it more graciously.
Check out the full pipeline JSON below. And remember to look out for the next blog post that will describe the second approach!
| { | |
| "name": "00_is_pipeline_running", | |
| "properties": { | |
| "activities": [ | |
| { | |
| "name": "Get Pipeline Runs", | |
| "type": "WebActivity", | |
| "dependsOn": [ | |
| { | |
| "activity": "getSubscriptionID", | |
| "dependencyConditions": [ | |
| "Succeeded" | |
| ] | |
| }, | |
| { | |
| "activity": "getAdfResourceGroupName", | |
| "dependencyConditions": [ | |
| "Succeeded" | |
| ] | |
| } | |
| ], | |
| "policy": { | |
| "timeout": "7.00:00:00", | |
| "retry": 0, | |
| "retryIntervalInSeconds": 30, | |
| "secureOutput": false, | |
| "secureInput": false | |
| }, | |
| "userProperties": [], | |
| "typeProperties": { | |
| "url": { | |
| "value": "https://management.azure.com/subscriptions/@{activity('getSubscriptionID').output.value}/resourceGroups/@{activity('getAdfResourceGroupName').output.value}/providers/Microsoft.DataFactory/factories/@{pipeline().DataFactory}/queryPipelineRuns?api-version=2018-06-01", | |
| "type": "Expression" | |
| }, | |
| "method": "POST", | |
| "body": { | |
| "value": "{\n \"lastUpdatedAfter\": \"@{adddays(utcnow(),int(pipeline().parameters.QueryRunDays))}\",\n \"lastUpdatedBefore\": \"@{utcnow()}\",\n \"filters\": [\n {\n \"operand\": \"PipelineName\",\n \"operator\": \"Equals\",\n \"values\": [\n \"@{pipeline().parameters.PipelineName}\"\n ]\n },\n { \n \"operand\": \"Status\", \n \"operator\": \"In\", \n \"values\": [ \n \"InProgress\", \n \"Queued\"\n ] \n }\n ]\n}", | |
| "type": "Expression" | |
| }, | |
| "authentication": { | |
| "type": "MSI", | |
| "resource": "https://management.core.windows.net/" | |
| } | |
| } | |
| }, | |
| { | |
| "name": "Filter Running Pipelines", | |
| "type": "Filter", | |
| "dependsOn": [ | |
| { | |
| "activity": "Get Pipeline Runs", | |
| "dependencyConditions": [ | |
| "Succeeded" | |
| ] | |
| } | |
| ], | |
| "userProperties": [], | |
| "typeProperties": { | |
| "items": { | |
| "value": "@activity('Get Pipeline Runs').output.value", | |
| "type": "Expression" | |
| }, | |
| "condition": { | |
| "value": "@and(not(equals(item().runId,pipeline().parameters.ThisRunId)),or(equals(item().status,'InProgress'),equals(item().status,'Queued')))", | |
| "type": "Expression" | |
| } | |
| } | |
| }, | |
| { | |
| "name": "If Pipeline Is Running", | |
| "type": "IfCondition", | |
| "dependsOn": [ | |
| { | |
| "activity": "Filter Running Pipelines", | |
| "dependencyConditions": [ | |
| "Succeeded" | |
| ] | |
| } | |
| ], | |
| "userProperties": [], | |
| "typeProperties": { | |
| "expression": { | |
| "value": "@greaterOrEquals(int(activity('Filter Running Pipelines').output.FilteredItemsCount),1)", | |
| "type": "Expression" | |
| }, | |
| "ifTrueActivities": [ | |
| { | |
| "name": "Raise Error", | |
| "type": "Lookup", | |
| "dependsOn": [], | |
| "policy": { | |
| "timeout": "7.00:00:00", | |
| "retry": null, | |
| "retryIntervalInSeconds": 30, | |
| "secureOutput": false, | |
| "secureInput": false | |
| }, | |
| "userProperties": [], | |
| "typeProperties": { | |
| "source": { | |
| "type": "AzureSqlSource", | |
| "sqlReaderQuery": { | |
| "value": "RAISERROR('@{concat('Provided pipeline name (',pipeline().parameters.PipelineName,') still has a run in progress or queued given the query range parameters set in the properties table.')}',16,1);", | |
| "type": "Expression" | |
| }, | |
| "queryTimeout": "02:00:00", | |
| "partitionOption": "None" | |
| }, | |
| "dataset": { | |
| "referenceName": "metadata", | |
| "type": "DatasetReference", | |
| "parameters": { | |
| "table": "dummy", | |
| "schema": "dummy" | |
| } | |
| }, | |
| "firstRowOnly": false | |
| } | |
| } | |
| ] | |
| } | |
| }, | |
| { | |
| "name": "getSubscriptionID", | |
| "type": "WebActivity", | |
| "dependsOn": [], | |
| "policy": { | |
| "timeout": "7.00:00:00", | |
| "retry": 3, | |
| "retryIntervalInSeconds": 30, | |
| "secureOutput": false, | |
| "secureInput": false | |
| }, | |
| "userProperties": [], | |
| "typeProperties": { | |
| "url": { | |
| "value": "@concat(pipeline().globalParameters.keyVaultUrl,'secrets/SubscriptionID?api-version=7.0')", | |
| "type": "Expression" | |
| }, | |
| "method": "GET", | |
| "authentication": { | |
| "type": "MSI", | |
| "resource": "https://vault.azure.net" | |
| } | |
| } | |
| }, | |
| { | |
| "name": "getAdfResourceGroupName", | |
| "type": "WebActivity", | |
| "dependsOn": [], | |
| "policy": { | |
| "timeout": "7.00:00:00", | |
| "retry": 3, | |
| "retryIntervalInSeconds": 30, | |
| "secureOutput": false, | |
| "secureInput": false | |
| }, | |
| "userProperties": [], | |
| "typeProperties": { | |
| "url": { | |
| "value": "@concat(pipeline().globalParameters.keyVaultUrl,'secrets/adfResourceGroupName?api-version=7.0')", | |
| "type": "Expression" | |
| }, | |
| "method": "GET", | |
| "authentication": { | |
| "type": "MSI", | |
| "resource": "https://vault.azure.net" | |
| } | |
| } | |
| } | |
| ], | |
| "parameters": { | |
| "PipelineName": { | |
| "type": "string" | |
| }, | |
| "ThisRunId": { | |
| "type": "string" | |
| }, | |
| "QueryRunDays": { | |
| "type": "string", | |
| "defaultValue": "-1" | |
| } | |
| }, | |
| "variables": { | |
| "SubscriptionId": { | |
| "type": "String" | |
| }, | |
| "RunCount": { | |
| "type": "String" | |
| } | |
| }, | |
| "folder": { | |
| "name": "_platform" | |
| }, | |
| "annotations": [] | |
| } | |
| } |
 by
by 

Hi guys, nice post, looking forward to reading next part.
Doesn’t “Concurrency” pipeline property work in your scenario?
Hi Riccardo, the Concurrency property will control it in such a way that it will form a queue of runs. If that is desired, then that will be the best option to use. In our use case that was not desired, so we had to think of an option to prevent concurrency and queuing.
Hi, I will go to extend, check/wait on each layer. Useful article. Thanks
Hi I have the question according to second options, how you want save lock info in global parameters ? As far as i know we can set their values before pipeline run but during the activity execution we can’t change their values
Mateusz, I think you’re right. The second solution would need a global *variable*, not a global parameter. I guess we could use an external resource, e.g. a database table or a blob store, for the same purpose.
The two solutions you present are quite good. I have a third solution, that I think is simpler, but might not work well in all circumstances. Use a blob file to coordinate the pipeline runs.
Call the file something like “Pipeline running check.txt.” At the beginning of the pipeline have it write a 1 to the blob and at the end of the pipeline have it write a 0 to the blob.
The traffic cop pipeline simply checks the file and doesn’t run the main pipeline if the file contains a 1.
The main issue with that approach is when the pipeline fails, the file still had a 1 in it.
Hi, after following all the above steps mentioned, still getting the below error
Invoking Web Activity failed with HttpStatusCode – ‘404 : NotFound’, message – ‘The requested resource does not exist on the server. Please verify the request server and retry'”,
Hi – thanks for the helpful article, I’ve implemented this solution and have been using it for a number of months in our development workspace. I have moved the pipelines to Production recently and I noticed something odd. When the duplicate pipeline check was running it was finding a duplicate in the other environment. The two environments are in different resource groups, the ADF’s only have access to their respective ADF’s. Any clues as to what might be the issue?