
My favorite architecture for modern data warehousing is the ‘ISPTMS’ approach. It clearly identifies layers for the most distinct ‘tasks’ we do involving data: INGEST, STORE, PREP, TRAIN, MODEL, and SERVE. This blogpost series will be about a new and exciting approach for the MODEL and SERVE layers in the architecture. Specifically, I will guide you on how to use meta-driven generated CDM folders in Azure Data Lake Storage, in conjunction with Power BI dataflows.
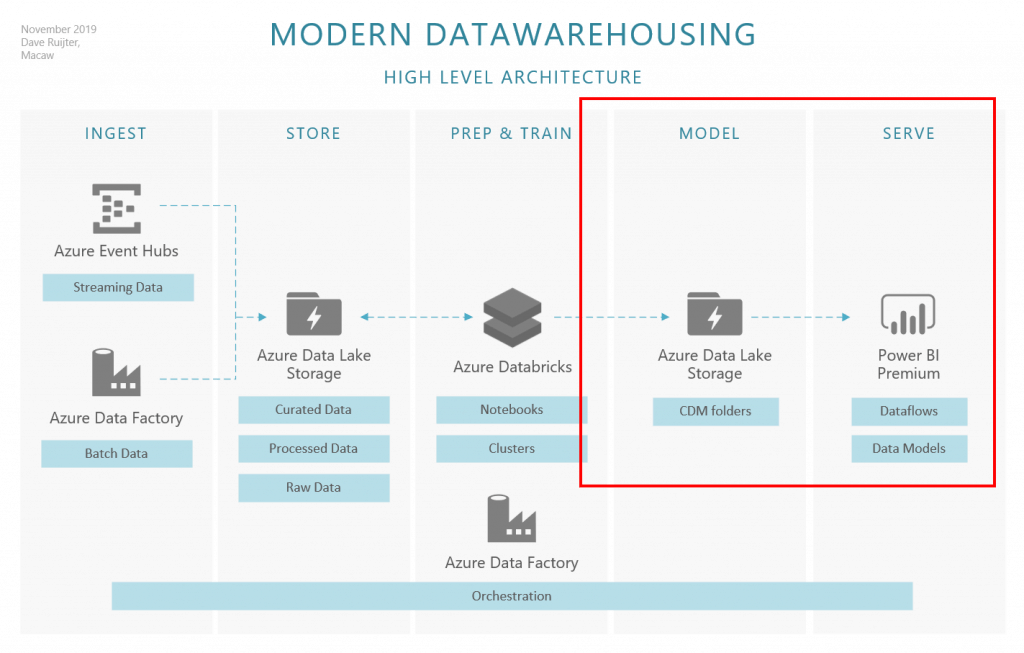
I am enthusiastic about this approach because I see clear benefits for both the data engineering as well as the data analysis domains. Connecting to dataflows from Power BI Desktop is easy and does not require any upfront knowledge about Data Platform service endpoints, server names or any of these technical properties. This can have a positive effect on the adoption and usage of your Data Platform (and the Power BI environment). As an extra benefit, the data is structured in CDM compliant folders, enabling consistency of data and its meaning across applications and business processes. And, if you look at how dataflows are growing in importance for the entire Power Platform – PowerApps is embracing dataflows, it is a smart move to deliver all datawarehousing data via dataflows.
From the data engineering perspective, we simplify the architecture by having a direct connection between the data in the Data Lake and the Power BI Service, skipping the traditional SQL Data Warehouse or SQL Database component. This saves time (and frustration here and there) to not having to build and maintain a database project in a metadata-driven architecture. Although of course we have to invest time and love in other (new) components, this feels like a net win. The engineers can focus more on the data preparations.
Meta-data driven
To make this method successful, we need to work out some ‘moving parts’. For instance, how do we create those CDM folders? Manually? That’s not an acceptable solution. In the second blog post, I will demonstrate a meta-data driven approach, creating and loading these CDM folders automagically.
Power BI dataflows & permissions
These CDM folders only really shine bright when mounted as dataflows inside the Power BI Service and the analysts have access to them. We can automate this process using the APIs provided for Azure Data Lake and Power BI. I will demonstrate how to set RBAC and ACLs to secure the CDM folders and make them available for use.
Orchestration
Of course, all ‘MODEL & SERVE’ activities will be managed smoothly by the #1 orchestrator in the Azure platform: Data Factory! Just like the rest of the data platform (scheduled) activities. I will walk you through the required setup, including some points of attention regarding the deployment of these parts using Azure DevOps releases.
I’ve got the following list of blog posts planned. Don’t expect them the coming week as I’ll be a little distracted because of the Microsoft Ignite conference 😎 (are you there as well, let’s meetup!).
- Part 2: Meta-data driven CDM folder creation using Azure Databricks (co-authoring with Anton Corredoira)
- Part 3: Securing CDM folders in your Azure Data Lake Storage
- Part 4: Orchestration of the MODEL & SERVE activities using Azure Data Factory
Pingback: Last Week Reading (2019-11-10) | SQLPlayer
Great article! Do you have parts 3 and 4 in the works?
Would love to learn more about orchestrating MODEL & SERVE activities.
Hi Steven, I have not finished those posts yet, unfortunately. If you DM me on Twitter we can do a little Q&A on it, to get your urgent questions sorted out?
I find it interesting you consider dataflows to be the new data warehousing storage layer, instead of Azure SQL DB/DWH.
When it comes to interoperability with other systems, are those solutions not more flexible, and do they not offer better performance.
A data warehouse (depending on how strict you want to consider that definition vs data mart / data hub ) may serve other consumers than Power BI.